
如果我们访问一个网站,只需要在浏览器中输入网站的域名,就可以请求到网站的服务器,得到我们想要的页面。这个过程很是短暂,但你知道他的过程是怎么的么?

今天就说一说一次完整的HTML请求的过程是怎么样的
解析URL
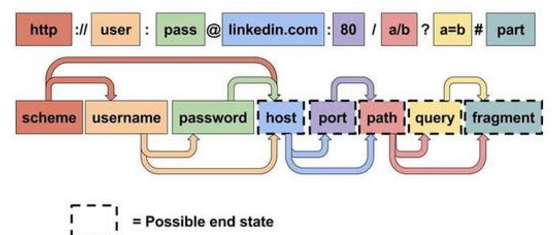
我向浏览器中输入网址后,浏览器会效验网址的合法性,如果网址不合法,会传给默认的搜索引擎。
如果网址合法并通过验证,浏览器会解析,得到协议(http或https),域名,资源页面(比如首面等)
DNS查询
浏览器会先检查域名信息是否在缓存中。
再检查域名是否在本地的Hosts文件中。
如果还不在,那么浏览器会向DNS服务器发送一个查询请求,获得目标服务器的IP地址。
TCP封包及传输
浏览器获得了目标服务器的IP(DNS返回)、端口(URL中包含,没有就使用默认),浏览器会调用库函数socket,生成一个TCP流套接字,也就是完成了TCP的封包。
得到服务器IP地址后,User-Agent(一般是指浏览器)会以一个随机端口(1024 < 端口 < 65535)向服务器的WEB程序的80端口发起TCP的连接请求。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后还有可能要经过防火墙的过滤,最终到达WEB程序,最终建立了TCP/IP的连接。
TCP封包完成之后,就可以传输了,在完成“你瞅啥”,“瞅你咋地”,“来,过来唠唠”一系列操作之后,浏览器和服务器就完成了TCP的三次握手,建立了连接,后面就可以请求服务器资源了。
建立TCP连接后发起HTTP请求
TCP3次握手后,浏览器发起了http的请求
HTTP请求报文格式,报文由3部分组成(请求行+请求头+请求体)
1、请求行:
①请求方法,GET、POST最常见,还有DELETE、HEAD、OPTIONS、PUT、TRACE。
②URL地址,它和报文头的Host属性组成完整的请求URL。
③协议名称及版本号。
2、请求头:
HTTP的报文头,报文头包含若干个属性,格式为“属性名:属性值”,服务端据此获取客户端的信息。与缓存相关的规则信息,均包含在header中
3、请求体:
它将一个页面表单中的组件值通过param1=value1¶m2=value2的键值对形式编码成一个格式化串,它承载多个请求参数的数据。不但报文体可以传递请求参数,请求URL也可以通过类似于“tuotiao.com?param1=value1¶m2=value2”的方式传递请求参数。
服务器接收请求并相应
服务器端WEB程序接收到http请求后,开始处理该请求,返回给浏览器html
一些常见状态码
200:成功
301:永久重定向, Location响应首部的值仍为当前URL,为隐藏重定向
302:临时重定向,显式重定向, Location响应首部的值为新的URL
304:Not Modified 未修改,本地缓存的资源文件
404:Not Found 请求的URL资源并不存在
500:Internal Server Error 服务器内部错误
502:Bad Gateway 连接不到服务器
504:Gateway Timeout 能连接服务器,但服务器未在规定时间内给响应
浏览器解析并渲染
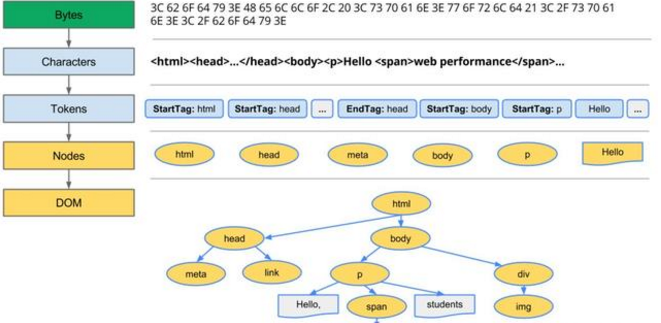
浏览器从服务器拿到了想要访问的资源,大多数时候,这个资源就是HTML页面,当然也可能是一个其他类型的文件。
浏览器先对HTML文档进行解析,生成解析树(以DOM元素为节点的树)。
加载页面的外部资源,比如JS、CSS、图片。
遍历DOM树,并计算每个节点的样式,最终完成渲染,变成我们看到的页面。




